-
陸小風和花滿樓聊鐵版神數
[size=13px]花滿樓看到一篇文章,說香港有位仁兄,研究鐵版神數7年未果轉投相信基督天主。拿給陸小風看。[/size]
[size=13px][/size]
[size=13px]陸小鳳是這樣說的:[/size]
[size=13px][/size]
[size=13px]只能說明韋千裡先生斷得不夠准確。用7年學會鐵版神數, 說明資質太愚鈍, 有古代數學基礎, 大概7小時就可以學會。
鐵版神數, 是一種編碼技術, 以乾大至兌小作為判斷的分區, 從樹根一直往樹梢不斷的傳遞生成樹。
學會是容易的, 關鍵是破解出來後, 理解古人為何推出這樣的結論。
比如六親屬相, 為何往往是年月日時天干的貴人?
繼續追溯下去, 就要探討到風水師天天使用的九宮飛星。
九宮飛星最早出自西漢太乙數。
屬於觀星象得出的結論。俺有這樣的感覺, 董慕節阮雲山對鐵版破解出來的結果理解不到百分之十。
因為從批文還看不到譬如斷一臂缺一腿那些結論。
說明就算算出來了還沒有把握不敢拿出來使用。
其次, 刻分是只中一網收最後的結果, 刻分越少, 推論出來的結果越多,
如子時1分和子時三刻1分, 那麼前者出來的信息量要比後者多很多。
不難發現, 董慕節對刻分越少的命, 批算的結果越含糊不敢下手。
不敢說外行看熱鬧內行看門道, 但你如果能找到董慕節有考出來刻分很低的命稿, 可以自行研究。綜上所敘, 董慕節阮雲山之流尚且未完全理解鐵版, 香港這麼一個普通的阿哥就能棄鐵版改信仰從主,
只能說明信仰自由, 和學術風馬牛不相及。[/size]
[size=13px][/size]
[size=13px]花滿樓突然記得以前看過一個Huffman哈夫曼編碼無損壓縮的代碼:[/size][size=13px]//———————————————————————————————[/size]
[size=13px] #include[/size]
[size=13px] #include[/size]
[size=13px] #include[/size]
[size=13px] #define DNUM 64 //define data number 8*8[/size]
[size=13px] #define LOOP 10000 //times of compression[/size]
[size=13px] typedef struct[/size]
[size=13px] {[/size]
[size=13px] unsigned short weight, data;[/size]
[size=13px] unsigned short parent, lchild, rchild;[/size]
[size=13px] } HuffNode;[/size]
[size=13px] typedef struct[/size]
[size=13px] {[/size]
[size=13px] unsigned char code;[/size]
[size=13px] unsigned short codelength;[/size]
[size=13px] } HuffCode;[/size]
[size=13px] unsigned int fCount[256] = {0};[/size]
[size=13px] unsigned int data_num;[/size]
[size=13px] unsigned int code_size;[/size]
[size=13px] unsigned int last_bit;[/size]
[size=13px] void FrequencyCount(unsigned char*); //频率统计[/size]
[size=13px] void HuffSelect(HuffNode*, int, int*, int*); //从结点中选出权最小的两个节点[/size]
[size=13px] void HuffmanCodeTable(HuffNode*, HuffCode*); //构造huffman树,生成huffman编码表[/size]
[size=13px] void HuffmanCompress(unsigned char*, unsigned char *, HuffCode*); //压缩数据[/size]
[size=13px] void BitPrint(unsigned char*); //按位打印结果,用于调试[/size]
[size=13px] void main()[/size]
[size=13px] {[/size]
[size=13px] int i, j, loop; //variable for loop[/size]
[size=13px] HuffNode hfdata[2*DNUM] = {{0, 0, 0, 0, 0}}; //Huffman node[/size]
[size=13px] HuffCode code_table[256] = {{0, 0}}; //code table will be searched by subscript[/size]
[size=13px] unsigned char hfcode[2*DNUM]; //output code[/size]
[size=13px] time_t time1, time2;[/size]
[size=13px] /* unsigned char pixel[DNUM] = {[/size]
[size=13px] 1,2,3,4, 1,2,3,4, 1,2,3,4, 1,1,1,1};[/size]
[size=13px] */[/size]
[size=13px] /* unsigned char pixel[DNUM] = {[/size]
[size=13px] 139,144,149,153,155,155,155,155,[/size]
[size=13px] 144,151,153,156,159,156,156,156,[/size]
[size=13px] 150,155,160,163,158,156,156,156,[/size]
[size=13px] 159,161,162,160,160,159,159,159,[/size]
[size=13px] 159,160,161,162,162,155,155,155,[/size]
[size=13px] 161,161,161,161,160,157,157,157,[/size]
[size=13px] 162,162,161,163,162,157,157,157,[/size]
[size=13px] 162,162,161,161,163,158,158,158};[/size]
[size=13px] */[/size]
[size=13px] unsigned char pixel[DNUM] = { //random data[/size]
[size=13px] 141, 101, 126, 111, 163, 112, 133, 156,[/size]
[size=13px] 103, 144, 111, 176, 117, 120, 188, 187,[/size]
[size=13px] 175, 164, 190, 156, 112, 179, 142, 119,[/size]
[size=13px] 140, 111, 127, 186, 196, 190, 189, 127,[/size]
[size=13px] 185, 103, 185, 110, 192, 139, 159, 104,[/size]
[size=13px] 151, 193, 178, 198, 114, 170, 179, 149,[/size]
[size=13px] 124, 149, 165, 108, 141, 176, 113, 164,[/size]
[size=13px] 101, 140, 120, 126, 173, 189, 158, 184};[/size]
[size=13px] /* unsigned char pixel[DNUM] = {[/size]
[size=13px] 202, 221, 159, 183, 41, 136, 247, 66,[/size]
[size=13px] 146, 29, 101, 108, 45, 61, 210, 236,[/size]
[size=13px] 90, 130, 54, 66, 132, 206, 119, 232,[/size]
[size=13px] 184, 135, 96, 78, 120, 41, 231, 203,[/size]
[size=13px] 150, 94, 172, 142, 122, 180, 150, 204,[/size]
[size=13px] 232, 121, 180, 221, 3, 207, 115, 147,[/size]
[size=13px] 72, 149, 169, 121, 76, 208, 235, 43,[/size]
[size=13px] 107, 58, 0, 237, 197, 7, 210, 89};[/size]
[size=13px] */[/size]
[size=13px] FrequencyCount(pixel);[/size]
[size=13px] time1 = time(NULL);[/size]
[size=13px] for (loop=0; loop
[size=13px] hfdata[j].weight = fCount;[/size]
[size=13px] hfdata[j++].data = i;[/size]
[size=13px] data_num ++;[/size]
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] //build huffman tree and generate huffman code table[/size]
[size=13px] HuffmanCodeTable(hfdata, code_table);[/size]
[size=13px] //compress source data to huffman code using code table[/size]
[size=13px] HuffmanCompress(pixel, hfcode, code_table);[/size]
[size=13px] //initial hfdata and code_table[/size]
[size=13px] for (j=0; j<2*DNUM; j++) {[/size]
[size=13px] hfdata[j].data=0;[/size]
[size=13px] hfdata[j].lchild=0;[/size]
[size=13px] hfdata[j].parent=0;[/size]
[size=13px] hfdata[j].rchild=0;[/size]
[size=13px] hfdata[j].weight=0;[/size]
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] time2 = time(NULL);[/size]
[size=13px] //conclude[/size]
[size=13px] printf("n哈夫曼编码压缩图块,压缩报告n华中科技大学力学系:李美之n");[/size]
[size=13px] printf("n◎源数据(%d字节):n ", DNUM);[/size]
[size=13px] for (i=0; i
[size=13px] }[/size]
[size=13px] printf(“t”);[/size]
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] printf(“nn◎压缩率:%2.0f%% t压缩时间:%.3f毫秒n”,(float)code_size/DNUM * 100, 1E3*(time2-time1)/LOOP);[/size]
[size=13px] }[/size]
[size=13px] void BitPrint(unsigned char *hfcode)[/size]
[size=13px] {[/size]
[size=13px] int i, j;[/size]
[size=13px] int endbit = last_bit;[/size]
[size=13px] unsigned char thebyte;[/size]
[size=13px] for (i=0; i < code_size-1; i++) {[/size] [size=13px] thebyte = hfcode;[/size] [size=13px] for (j=0; j<8; j++) {[/size] [size=13px] printf("%d", ((thebyte<
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] if (last_bit == 7) {[/size]
[size=13px] endbit = -1;[/size]
[size=13px] }[/size]
[size=13px] thebyte = hfcode;[/size]
[size=13px] for (j=7; j>endbit; j–) {[/size]
[size=13px] printf(“%d”, ((thebyte<<(7-j))&0x80)>>7);[/size]
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] void HuffmanCompress(unsigned char *pixel, unsigned char *hfcode, HuffCode * code_table)[/size]
[size=13px] {[/size]
[size=13px] int i, j;[/size]
[size=13px] int curbit=7; //current bit in _thebyte_[/size]
[size=13px] unsigned int bytenum=0; //number of destination code can also be position of byte processed in destination[/size]
[size=13px] unsigned int ptbyte=0; //position of byte processed in destination[/size]
[size=13px] unsigned int curlength; //code’s length of _curcode_[/size]
[size=13px] unsigned char curcode; //current byte’s huffman code[/size]
[size=13px] unsigned char thebyte=0; //destination byte write[/size]
[size=13px] unsigned char value; //current byte’s value (pixel[])[/size]
[size=13px] //process every byte[/size]
[size=13px] for (i=0; i
[size=13px] else curcode = (curcode >> 1) | 0x80; //0x80 = 128 = B1000 0000[/size]
[size=13px] }[/size]
[size=13px] code_table[hfdata.data].code = curcode;[/size]
[size=13px] code_table[hfdata.data].codelength = curlength;[/size]
[size=13px] }[/size]
[size=13px] }[/size]
[size=13px] void HuffSelect(HuffNode *hfdata, int end, int *min1, int *min2)[/size]
[size=13px] {[/size]
[size=13px] int i; //variable for loop[/size]
[size=13px] int s1, s2;[/size]
[size=13px] HuffNode wath[30];[/size]
[size=13px] for (i=0; i<30; i++) {[/size]
[size=13px] wath = hfdata;[/size]
[size=13px] }[/size]
[size=13px] s1 = s2 = 1;[/size]
[size=13px] while (hfdata[s1].parent) {[/size]
[size=13px] s1++;[/size]
[size=13px] }[/size]
[size=13px] for (i=2; i<=end; i++) {[/size] [size=13px] if (hfdata.parent == 0 && hfdata.weight < hfdata[s1].weight) {[/size] [size=13px] s1 = i;[/size] [size=13px] }[/size] [size=13px] }[/size] [size=13px] while (hfdata[s2].parent || s1 == s2) {[/size] [size=13px] s2++;[/size] [size=13px] }[/size] [size=13px] for (i=1; i<=end; i++) {[/size] [size=13px] if (hfdata.parent ==0 && hfdata.weight < hfdata[s2].weight && (i - s1)) {[/size] [size=13px] s2 = i;[/size] [size=13px] }[/size] [size=13px] }[/size] [size=13px] *min1 = s1;[/size] [size=13px] *min2 = s2;[/size] [size=13px] }[/size] [size=13px] void FrequencyCount(unsigned char *chs)[/size] [size=13px] {[/size] [size=13px] int i;[/size] [size=13px] for (i=0; i
//——————————————————–[/size]
[size=13px]看到下面这些有了顿悟[/size]
[size=13px][size=13px] /* unsigned char pixel[DNUM] = {[/size]
[size=13px] 139,144,149,153,155,155,155,155,[/size]
[size=13px] 144,151,153,156,159,156,156,156,[/size]
[size=13px] 150,155,160,163,158,156,156,156,[/size]
[size=13px] 159,161,162,160,160,159,159,159,[/size]
[size=13px] 159,160,161,162,162,155,155,155,[/size]
[size=13px] 161,161,161,161,160,157,157,157,[/size]
[size=13px] 162,162,161,163,162,157,157,157,[/size]
[size=13px] 162,162,161,161,163,158,158,158};[/size]
[size=13px] */[/size]
[size=13px] unsigned char pixel[DNUM] = { //random data[/size]
[size=13px] 141, 101, 126, 111, 163, 112, 133, 156,[/size]
[size=13px] 103, 144, 111, 176, 117, 120, 188, 187,[/size]
[size=13px] 175, 164, 190, 156, 112, 179, 142, 119,[/size]
[size=13px] 140, 111, 127, 186, 196, 190, 189, 127,[/size]
[size=13px] 185, 103, 185, 110, 192, 139, 159, 104,[/size]
[size=13px] 151, 193, 178, 198, 114, 170, 179, 149,[/size]
[size=13px] 124, 149, 165, 108, 141, 176, 113, 164,[/size]
[size=13px] 101, 140, 120, 126, 173, 189, 158, 184};[/size]
[size=13px] /* unsigned char pixel[DNUM] = {[/size]
[size=13px] 202, 221, 159, 183, 41, 136, 247, 66,[/size]
[size=13px] 146, 29, 101, 108, 45, 61, 210, 236,[/size]
[size=13px] 90, 130, 54, 66, 132, 206, 119, 232,[/size]
[size=13px] 184, 135, 96, 78, 120, 41, 231, 203,[/size]
[size=13px] 150, 94, 172, 142, 122, 180, 150, 204,[/size]
[size=13px] 232, 121, 180, 221, 3, 207, 115, 147,[/size]
[size=13px] 72, 149, 169, 121, 76, 208, 235, 43,[/size]
[size=13px] 107, 58, 0, 237, 197, 7, 210, 89};[/size]花滿樓再想起一篇關於編碼的介紹
1.2 Huffman编码简介[/size]
[size=13px]1.2.1 Huffman编码的压缩原理[/size]
[size=13px]我们把文件中一定位长的值看作是符号,比如把8位长的256种值,也就是字节的256种值看作是符号。我们根据这些符号在文件中出现的频率,对这些符号重新编码。对于出现次数非常多的,我们用较少的位来表示,对于出现次数非常少的,我们用较多的位来表示。这样一来,文件的一些部分位数变少了,一些部分位数变多了,由于变小的部分比变大的部分多,所以整个文件的大小还是会减小,所以文件得到了压缩。[/size]
[size=13px]1.2.2 Huffman编码使用Huffman树来产生编码[/size]
[size=13px]要进行Huffman编码,首先要把整个文件读一遍,在读的过程中,统计每个符号(我们把字节的256种值看作是256种符号)的出现次数。然后根据符号的出现次数,建立Huffman树,通过Huffman树得到每个符号的新的编码。对于文件中出现次数较多的符号,它的Huffman编码的位数比较少。对于文件中出现次数较少的符号,它的Huffman编码的位数比较多。然后把文件中的每个字节替换成他们新的编码。[/size]
[size=13px]建立Huffman树:[/size]
[size=13px]把所有符号看成是一个结点,并且该结点的值为它的出现次数。进一步把这些结点看成是只有一个结点的树。[/size]
[size=13px]每次从所有树中找出值最小的两个树,为这两个树建立一个父结点,然后这两个树和它们的父结点组成一个新的树,这个新的树的值为它的两个子树的值的和。如此往复,直到最后所有的树变成了一棵树。我们就得到了一棵Huffman树。[/size]
[size=13px]通过Huffman树得到Huffman编码:[/size]
[size=13px]这棵Huffman树,是一棵二叉树,它的所有叶子结点就是所有的符号,它的中间结点是在产生Huffman树的过程中不断建立的。[/size]
[size=13px]我们在Huffman树的所有父结点到它的左子结点的路径上标上0,右子结点的路径上标上1。[/size]
[size=13px]现在我们从根节点开始,到所有叶子结点的路径,就是一个0和1的序列。我们用根结点到一个叶子结点路径上的0和1的序列,作为这个叶子结点的Huffman编码。[/size]
[size=13px][/size]
[size=13px]
我们可以看到,Huffman树的建立方法就保证了,出现次数多的符号,得到的Huffman编码位数少,出现次数少的符号,得到的Huffman编码位数多。
各个符号的Huffman编码的长度不一,也就是变长编码。对于变长编码,可能会遇到一个问题,就是重新编码的文件中可能会无法如区分这些编码。
比如,a的编码为000,b的编码为0001,c的编码为1,那么当遇到0001时,就不知道0001代表ac,还是代表b。出现这种问题的原因是a的编码是b的编码的前缀。
由于Huffman编码为根结点到叶子结点路径上的0和1的序列,而一个叶子结点的路径不可能是另一个叶子结点路径的前缀,所以一个Huffman编码不可能为另一个Huffman编码的前缀,这就保证了Huffman编码是可以区分的。
1.2.3 使用Huffman编码进行压缩和解压缩
为了在解压缩的时候,得到压缩时所使用的Huffman树,我们需要在压缩文件中,保存树的信息,也就是保存每个符号的出现次数的信息。
压缩:
读文件,统计每个符号的出现次数。根据每个符号的出现次数,建立Huffman树,得到每个符号的Huffman编码。将每个符号的出现次数的信息保存在压缩文件中,将文件中的每个符号替换成它的Huffman编码,并输出。
解压缩:
得到保存在压缩文件中的,每个符号的出现次数的信息。根据每个符号的出现次数,建立Huffman树,得到每个符号的Huffman编码。将压缩文件中的每个Huffman编码替换成它对应的符号,并输出。花滿樓又想起算術編碼[/size]
越看越覺得ABCD這些跟乾坤艮兌都是差不多的, 網名叫花滿樓,別名叫牛人大叔也不是不可以~~~
董慕節一九四八年開始學八字,一九五二年在上海大觀園執業算命。Huffman 編碼是一種編碼方式,是一種用於無損數據壓縮的熵編碼(權編碼)算法。1952年,David A. Huffman在麻省理工攻讀博士時所發明的。顯然,鐵版神數不是用Huffman, 那麼會是什麼算法呢?
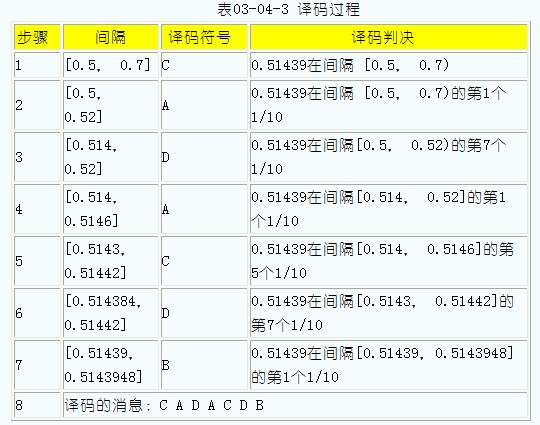
陸小鳳笑笑對花滿樓遞過《續古摘奇算法》說: 好好看吧, 俺要恰飯了~~~
[ 本帖最後由 汕頭黃祖和 於 2011-10-1 06:30 PM 編輯 ]




Log in to reply.